DataTribune
Projets Data Analytics : et si vous adoptiez (enfin) les méthodologies agiles ? si, si… c’est possible !

Les projets de DATA ANALYTICS tombent souvent dans les travers de la gestion de projet en « cycle V ». Ce dernier n’est pas pour autant à jeter. Après tout, il a fait ses preuves pour des processus support par exemple ou des besoins plus standardisés. Et bien, il n’en reste pas moins en contradiction forte avec l’agilité supposée que doit permettre et produire la DATA. En ce cas, le temps est peut-être venu de concevoir et produire les projets DATA ANALYTICS en mode agile ! Et cela tombe plutôt bien… parce que 1. c’est possible… si si ! Et 2. on vous explique même comment 😉
DATA ANALYTICS ET AGILITÉ N’ONT LONGTEMPS RIMÉ QUE SUR LE PAPIER !
Être Agile dans un projet « Data Analytics » semble être une gageure de prime abord. En effet, la construction d’applications analytiques nécessite d’avoir à disposition les données, avec un certain nombre de critères respectés :
- Qualité suffisante ;
- Profondeur d’historique nécessaire ;
- Bonne organisation (pour des requêtes performantes) ;
- Disponibilité (pour ne pas pénaliser les applications sources).
Ainsi, contrairement à des applications transactionnelles, où il est possible de construire l’enveloppe en se basant sur des données tests, les applications analytiques impliquent de travailler sur des données suffisamment représentatives, pour concevoir les bonnes analyses.
Historiquement, un projet analytique se construisait sur une double approche :
- Top-down pour connaître les besoins d’analyse permettant de travailler sur la modélisation des donnés (visant des requêtes performantes, à travers la définition précise des indicateurs et des axes d’analyse) et leur disponibilité (construction d’une base type datawarehouse ou datamart)
- Bottom-up pour étudier la faisabilité (qualité des données, accessibilité des sources et profondeur d’historique).
LE SEMPITERNEL CYCLE V… OU L’IMPOSSIBILITÉ DE CRÉER DE LA VALEUR À COURT TERME
Cette approche imposait malheureusement un cycle en V, avec un effet tunnel inhérent. Pour construire le socle de données nécessaire (le datawarehouse et les datamarts), il fallait passer par une étape longue de spécifications avec les métiers. Ces derniers devaient alors s’engager, sans même pouvoir voir les résultats sur les analyses attendues (indicateurs et axes d’analyse).
Une fois que les métiers avaient « signé avec leur sang » les spécifications, alors – et seulement alors – les développements IT pouvaient commencer.
Les résultats n’étaient ainsi visibles que lors de la recette, avec bien souvent un écart important entre le réalisé et l’attendu (sans parler des besoins qui avaient pu évoluer entre temps).
Finalement, l’architecture mise en œuvre présentait un certain nombre de points durs, comme rappelés ci-dessous.
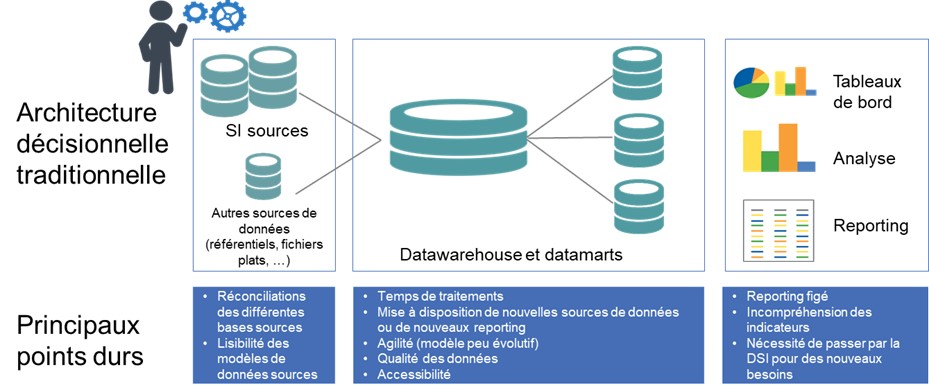
LE CYCLE V : UN CONSTAT MITIGÉ ET DE LOURDES PÉNALITÉS CÔTÉ MÉTIERS
Bref, le constat sur l’architecture décisionnelle traditionnelle est donc plus que mitigé :
- Nécessité de devoir réconcilier des données de multiples sources, en partant des besoins d’analyse ;
- Manque de précision dans la formulation des besoins : la difficulté à se projeter dans les besoins analytiques est un frein important pour la conception d’un décisionnel traditionnel ;
- Moyens humains souvent insuffisants : notamment techniques, un décisionnel traditionnel nécessitant des compétences pointues en ETL ou en base de données ;
- Mauvaise qualité des données : le décisionnel est souvent le révélateur de cet état de fait ;
- Nombreux destinataires pour le pilotage avec des besoins différents : études ponctuelles et urgentes pour la Direction Générale, reporting régulier pour les directions métiers, reporting opérationnel…
- Nouveaux usages mal adressés : data science, self-service BI…
Avec des conséquences lourdes pour les métiers :
- Beaucoup de temps passé à récolter, consolider et mettre en forme l’information au détriment de l’analyse et d’une véritable valeur ajoutée métier ;
- Un décisionnel coûteux en regard des services rendus : tout changement des données sources ou des besoins utilisateurs nécessite des développements conséquents du fait des impacts sur toute la chaîne décisionnelle ;
- À terme, un discrédit sur la capacité à répondre aux enjeux stratégiques de l’organisation et à mettre en œuvre de nouveaux usages.
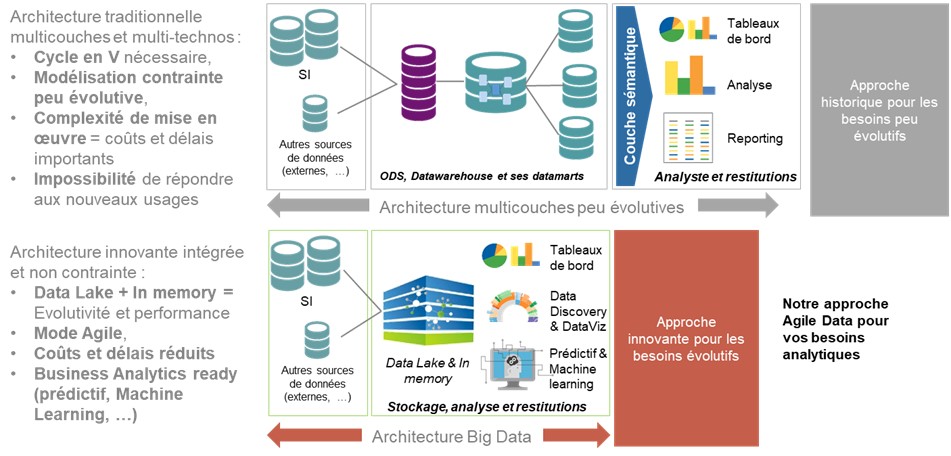
« L’AGILE DATA » OU LA RÉVOLUTION AGILE DES (PROJETS) DATA !
Au regard des constats précités, il semblait donc nécessaire de proposer une démarche agile, appliquée aux projets Data Analytics.
Notre démarche repose sur une offre complète, à la fois :
- Technologique, par la mise en place d’une architecture data non -contrainte (un datalake) et des solutions adaptées aux différents usages ;
- Méthodologique, par l’adoption des principes d’une démarche Agile (en co-construction avec les métiers) ;
- Outillée avec notre « Agile Data Toolkit», permettant d’industrialiser l’ensemble de la chaîne technique.
Premier principe : miser sur un socle de données non contraint
Il consiste à mettre en place un socle de données non contraint (datalake), agnostique des usages futurs, mais qui permette d’organiser les données suivant les caractéristiques suivantes :
- Orientées métier(et non pas usages) : les données sont modélisées en regard des concepts métiers sous-jacents et des sources de données ;
- Intégrées: les données sont unifiées dans le socle, en termes de référentiels et de formats ;
- Historisées: toutes les données sont taguées par une variable temporelle
- Non volatiles: les données sont permanentes, c’est-à-dire que lorsque de nouvelles données sont insérées, les données précédentes ne sont pas remplacées, omises ou supprimées.
Second principe : co-construire avec le métier, en agile !
Il consiste à coconstruire les applications analytiques avec les métiers, en sprints, en travaillant sur des données réelles.
Cela permet de rester au plus proche des besoins métiers, tout en appréhendant au fur et à mesure les inévitables cas particuliers, liés à des règles de gestion spécifiques et à la qualité réelle des données.
Troisième principe : favoriser l’appropriation côté users, au fil de l’eau…
Il consiste à favoriser l’appropriation par les utilisateurs, en leur mettant à disposition au fur et à mesure les applications lors des sprints. Cela permet d’avoir les retours métiers rapidement, afin de les intégrer dans les développements.
Il favorise également la conduite du changement et prépare la validation finale.
En synthèse : des gains importants, aussi bien sur les coûts immédiats que d’évolution !
Notre approche « Agile Data » permet des gains importants, tant en ce qui concerne les coûts d’implémentation que des coûts d’évolution. Le tout en ouvrant la possibilité de valoriser les données à travers de nouveaux usages.
Elle apporte donc des gains significatifs en regard des approches historique de datawarehousing.
Jean-Baptiste HUCK
